
Gary Illyes from Google has posted a blog entry on the Google Webmaster blog, touching on Googlebot and crawl budget issues that site owners might have.
First, it is important to note that not all site owners will be impacted by crawl budget issues. For the most part, sites with 4,000 or fewer URLs generally won’t have crawl budget issues. And for sites that run in the millions, crawl budget can be an issue that needs careful consideration and management.
For massive sites, a mismanaged crawl budget can mean the difference between ensuring your most important pages are indexed well… and them not being indexed at all.
We also have some additional clarification and comments from Gary Illyes on some specific aspects of crawl budget that weren’t discussed in the official Google blog post.
Contents
- 1 Crawl Budget is Not Related to Ranking Factor
- 2 Differences Between Crawl Rate Limit & Crawl Demand
- 3 New Sites Get Default Crawl Rate
- 4 Health of Site Matters
- 5 Site Speed
- 6 Popularity Matters
- 7 Stale URLs
- 8 AMP Uses Crawl Budget
- 9 Hreflang Uses Crawl Budget
- 10 CSS & Javascript Use Crawl Budget
- 11 Caching Resources to Preserve Crawl Budget
- 12 Crawl Budget & Sitemaps
- 13 Site Moves
- 14 Sudden Increase in Crawl Rate
- 15 Decrease in Crawl Rate
- 16 Varied Crawl Rates Per URL on Same Site
- 17 Crawl Priority
- 18 Crawl Schedules
- 19 How Googlebot Chooses URLs to Crawl
- 20 Google Ignoring Some Pages When Crawling
- 21 Internal Links Impact on Crawl Budget
- 22 Nofollow & Crawl Budget
- 23 Noindex & Crawl Budget
- 24 Canonicals & Crawl Budget
- 25 Crawl Budget & CMS / Forums / eCommerce Software
- 26 Impact of Server Errors
- 27 Lengthy Redirect Chains
- 28 RankBrain & Crawl Budget
- 29 Googlebot Ignores Crawl-Delay
- 30 Changing Googlebot Crawl Rate
- 31 Fix “Low Value” Pages
- 32 Final Thoughts on Crawl Budget
Crawl Budget is Not Related to Ranking Factor
Often site owners are concerned that Googlebot isn’t crawling their pages as frequently as they should, and it is hurting their rankings. Google has said multiple times previously that indexing frequency is not related to ranking. And they confirm once again that crawl rate is not directly related to ranking. But many people still believe that increasing a site’s crawl budget = higher rankings.
An increased crawl rate will not necessarily lead to better positions in Search results. Google uses hundreds of signals to rank the results, and while crawling is necessary for being in the results, it’s not a ranking signal.
That said, increasing crawl budget can mean that some pages that may not have been indexed previously on very large sites may end up getting indexed, which in turn could rank for keywords and bring traffic. This is why it can be very important for massive sites to ensure they are getting as much out of their crawl budget as possible.
Differences Between Crawl Rate Limit & Crawl Demand
It is important to note exactly what Google means by both these terms, which combined make up what we know as crawl budget.
Crawl rate limit refers to the rate which Googlebot actively crawls a site. It is determined by crawl health – how the server is responding to Googlebot crawling – and sometimes by the maximum crawl rate that a webmaster tells Googlebot to crawl, via a setting in Google Search Console.
Crawl demand refers to how many URLs Googlebot wants to crawl on a site, based on Google’s determination about the URLs to crawl, how frequently to crawl them, and to ensure that less frequently visited URLs still get scheduled for crawling. There is no guarantee, however, that Google will crawl all the pages on your site, even if your server is responding quickly.
New Sites Get Default Crawl Rate
I asked Gary Illyes from Google about how Google determines crawl budget for a site, particularly for new sites. And he revealed that every new site gets a default crawl rate limit to begin with. So large or small, sites all start the same.
“Every new site gets a default crawl rate limit, which may change over time as indexing figures out the demand,” Illyes confirmed to The SEM Post.
This is pretty interesting. We have often seen new large sites seemingly ramp up in the number of pages that get indexed, and this would be reflective of Google adjusting that default crawl rate while it is determining how fast or how much Googlebot can crawl.
Health of Site Matters
If you have a large site, Google looks at both server speed and server response time when looking at crawl budget. If your server is speedy without server errors, expect a higher crawl budget than if your site is slower to respond or throws 5xx server errors to Googlebot.
Don’t forget it isn’t always server speed specific that would impact this. Perhaps your database is clunky, and it responds slowly. Or maybe your CMS is old and outdated, and it is resulting in the slow delivery of the content on the page.
Site Speed
You have probably heard it a lot that speed matters. And this is especially true for your crawl budget. If you want to make the most of your crawl budget, you need to make sure Googlebot isn’t throttling the crawl on your site because it is slow enough responding that Google is worried it might be crashing the server.
While Google is often not specific in speed numbers, John Mueller did remark that a response time of two seconds resulted in a greatly reduced crawl budget on the site in question.
We’re seeing an extremely high response-time for requests made to your site (at times, over 2 seconds to fetch a single URL). This has resulted in us severely limiting the number of URLs we’ll crawl from your site, and you’re seeing that in Fetch as Google as well.
However, for those with slow sites, it doesn’t mean you are stuck at a low crawl rate forever. Site speed can have a greater impact over time, meaning even if your site is slow now, Google can see when it speeds up. If Googlebot knows your site responds “really quickly for a while,” then it will up the crawl rate. So if you know your site is slow and your server response time is slow, changing to a faster site/server will change Googlebot crawl frequency. As it recognizes the new speediness, it will start increasing crawl rate.
As our systems see a reduced response-time, they’ll automatically ramp crawling back up (which gives you more room to use Fetch as Google too).
That said, just because your server CAN handle Googlebot crawling more frequently, doesn’t mean it necessarily will.
Even if the crawl rate limit isn’t reached, if there’s no demand from indexing, there will be low activity from Googlebot.
It is also worth noting that page speed is also not a ranking factor. From a ranking perspective, Google is likely to negatively impact a very slow site, though.
Popularity Matters
When it comes to deciding when and how often Googlebot will crawl, Google clearly says that they will crawl pages they determine are popular pages more often, meaning those particular pages will be updated more frequently and be fresher in the search results.
URLs that are more popular on the Internet tend to be crawled more often to keep them fresher in our index.
Some popular URLs can get crawled many, many times per day, even if other pages on the site don’t get crawled as frequently.
But what exactly is Google using to determine popularity? Google would not share any more details on this, and it is likely because spammers could game it. However, there are definitely some signals, such as PageRank / links (both internal and external), impressions in the search results, clicks, and just that it is a high quality content page, which are pretty likely to be in the signal mix.
However, there is another perspective at popularity that could play a role most people don’t consider – if you have a high quality site, it could be looking at the most popular pages on each site, rather than just the more obvious “Google keeps recrawling the most popular pages on the web.” But what Google thinks is popular might not match with what pages you think are most important.
Stale URLs
Google has also specifically said that they try to not let URLs become stale in the index – but they don’t specify how stale that is.
Our systems attempt to prevent URLs from becoming stale in the index.
But it isn’t uncommon to see some URLs that haven’t been crawled for months when you check server logs or Google cache. For the most part, though, these tend to be pages that haven’t been changed for a very long time, so Google assumes that those URLs likely haven’t changed recently.
But eventually, Google will get around to crawling even these pages, because perhaps the content has changed since its last crawl of the page, and it might not still be reflective of the title and snippet they are currently showing in the search results. And that doesn’t make for a good user experience for Google’s searchers.
Poor quality pages tend to be crawled less frequently because there is less value for Google to show these poor quality pages to searchers. Unless you are in a market area with extremely low competition, which can sometimes happen in non-English languages, then there are likely many more higher quality pages for Google to spend its time on.
AMP Uses Crawl Budget
Dave Besbris, VP of Engineering at Google said last year that AMP does use crawl budget since Google still needs to crawl those pages. However, that was when Google was only showing AMP in the top news carousel for mobile users, well before Google announced AMP in the ten blue links of the main search results.
Google is confirming that AMP is still using crawl budget, again because Google still needs to crawl those AMP pages to check for any AMP errors as well as ensure that the content on the regular webpage matches what is on the AMP version.
This one is pretty significant for large sites. For sites having issues with crawl budget, adding AMP could greatly impact that. In these cases, it might be a better idea to test AMP smaller scale first, such as within a specific section or only on specific popular pages, rather than unleashing millions of AMP pages at once and hope the already poor crawl budget doesn’t suffer more.
Hreflang Uses Crawl Budget
Hreflang alternate URLs also use crawl budget. Google needs to ensure that the pages are identical or similar, and that some of the pages are not redirecting to spam or other content.
So keep this in mind if you have crawl budget issues when you have many alternate versions of the same page for hreflang purposes, each of those individual pages you use for alternate languages/regions will impact crawl budget.
CSS & Javascript Use Crawl Budget
Likewise, all those CSS & Javascript files you use on your site also consume crawl budget. While Google has long advocated combining CSS and Javascript files for site speed reasons, I suspect many aren’t aware that each of these individual files are also part of a site’s overall crawl budget.
Years ago, Google wasn’t crawling these files, so it wasn’t that big of an issue. But since Google started crawling them, especially for rendering pages for things like where the ads appear on the page, what is above the fold, and what might be hidden, many people still haven’t put time into optimizing these files.
I asked Gary Illyes from Google whether Googlebot will download files such as CSS and Javascript on every single page view, or if it would recognize they were the same and only crawl the file once. “It varies based on caching directives,” Illyes said.
Caching Resources to Preserve Crawl Budget
If you use any kind of site speed plugin on your site, you might already be leveraging caching for resources for bots. But if not, Cache-Control can be added either to the file being crawled or as added to your .htaccess, which is often the easiest implementation solution.
If your site utilizes an abundance of resources such as multiple CSS and Javascript files, implementing Cache-Control is a smart thing to do for technical reasons too, and Googlebot won’t be the only benefit. Site speed is usually improved, and that also benefits your site visitors too.
Don’t forget it is quite common for WordPress plugins to add their own CSS and JS to each page, whether the page uses the plugin or not. So if you have 15 plugins installed, you could be adding an additional 30+ resources that Google will need to crawl on each page. In these cases, it is easy to see how caching would preserve crawl budget.
Crawl Budget & Sitemaps
Sitemaps do play an important role in crawl budget. Google will prioritize URLs that are listed in a sitemap over URLs that are not in the sitemap that they discover independently, either through internal links on the site or external links.
But this only applies when you submit a partial sitemap to Google – on a large site it won’t prioritize every single URL on a site simply because it is one of the automated sitemaps that contains every single URL on the site.
If this URL is in a sitemap, we will probably want to crawl it sooner or more often because you deemed that page more important by putting it into a sitemap. We can also learn that this might not be true when sitemaps are automatically generated, like for every single URL entry in the sitemap.
So if you plan to use sitemaps to ensure Google is indexing the most important pages on a very large site, playing with partial sitemaps could be an option.
The other advantage to this method is it can be a bit easier to check the index status of your most important pages, and a bit easier to identify any in that important group that aren’t being indexed and/or crawled. And there are other benefits to using multiple or partial sitemaps too.
Also, there is no need to resubmit a sitemap regularly to increase crawl rate.
Site Moves
Google tends to crawl a site with higher frequency if a site move has taken place. This would include things like switching over to https or even a significant site structure change. Google has been quite vocal about wanting to ensure that sites switching to https are crawled by Googlebot as quickly as possible so more site owners will make the secure switch.
And while Google will noticeably increase the crawl frequency in order to index the new URLs and match them to the URLs (if you have done redirects correctly), it doesn’t mean this increased crawl rate is directly related to rankings, although it does mean you will retain your rankings much faster.
If you do make a site move and Googlebot is hitting the site too hard as it recrawls everything quickly, you can always temporarily drop the crawl rate limit for a couple of days. But don’t forget to revert it back and see if regular Googlebot crawling is fine.
Sudden Increase in Crawl Rate
While most sites view a suddenly increased crawl rate as a good thing, sometimes some site owners try and read something into a spike in crawl rate. But often it is just Googlebot doing its thing.
why we might crawl more are things that sometimes don’t even have much to do with the website, where our algorithms just decide oh, I want to double check all those URLs that I found on that website a while back and it just goes off and does that and suddenly we’re crawling twice as much for a couple of days and it doesn’t really mean that anything is a problem or anything that you need to worry about.
It is important to note that an increased crawl rate doesn’t directly equal increased rankings, especially if that increased crawl rate isn’t due to newly discovered URLs. Many times you will see a spike and not see a clear reason for why.
Google has also confirmed that an increase in crawl rate does not mean that there is a change in Google’s algo (although there are algo changes happening regularly) or a sign that manual actions are coming. Likewise, the increase in crawl rate does not mean a site is being hit with Panda (or that Panda is being lifted), nor is it a sign that something is impacting the site algorithmically. They also confirmed the change to real-time Penguin did not trigger an increased crawl rate either.
It also doesn’t mean that Google is changing something in their algorithm either.
But the crawling side wouldn’t necessarily be changed dramatically if one of the ranking algorithms were updated.
However, when you see a sudden increase in crawl rate after a site move, a change to https or URL structure change, that is perfectly normal, and Google is working on ensuring the old URLs are matched up to the new-and-improved URLs.
Decrease in Crawl Rate
On the flip side, though, if Google identifies a site as being spammy, Google doesn’t put a lot of priority on crawling those pages.
If this website is kind of a low quality site that we don’t really care about, then we’re not going to value that that much anyway. So crawling faster isn’t really something that we think makes sense there, its not going to have a big effect anyway.
From the disavow file information we have learned that sometimes Googlebot might not crawl a URL for 9 months, and those are pages that tend to be pretty low quality and spammy.
Varied Crawl Rates Per URL on Same Site
Even on a site, there isn’t a one size fits all scenario for crawl rates. A site can have different crawl rates on a per URL basis.
Per-URL crawl rates differ. Some URLs are crawled every few minutes, others just every couple months, and many somewhere in between.
When you do have a site with such varied rates, it is probably a signal that you should look at those pages that are crawled quite infrequently by comparison and see if they are low value pages that should be removed or noindexed. But they could simply be examples of evergreen content Google recognizes that hasn’t been changed in years, so it doesn’t feel the need to crawl it more frequently.
It’s not true that if a page isn’t crawled regularly that it won’t show up in rankings at all. In general we try to do our crawling based on when we think this page might be changing or how often it might be changing. So if we think that something stays the same for a longer period of time, we might not crawl it for a couple of months. And that’s completely fine. We can still show it in search.
As always, before you remove any pages for perceived low quality reasons, check your analytics to see whether those particular pages are getting traffic or not.
Crawl Priority
Just as Google can have a varied crawl rate on different URLs on a site, Google has different pages on a different crawl priority. For many sites – but not all – Google considers the homepage as the page with the highest priority for crawling, which is why if you look at server logs, it is likely the page with the most crawls by Googlebot.
But plenty of other factors could come into play on how Google is determining priority, such as PageRank / links, popularity, and even if a page hasn’t been crawled in quite some time and it needs a higher priority for a recrawl to happen.
Gary Illyes went into some detail on this specifically with a virtual keynote last year.
For example, high PageRank URLs probably should be crawled more often. And we have a bunch of other signals that we use that I will not say. But basically the more important the URL is the more often it will be recrawled. And once we recrawl the bucket of URLs of high importance URLs, then we will just stop, we will probably not go further..
Crawl Schedules
We do know that Google created a schedule for crawling URLs. From one site, you might see the homepage crawled at least once per day, and often much more than that. But other URLs might be set on a less frequent schedule, based on how important or how popular Google thinks those URLs are.
Gary Illyes went into some detail on this specifically with a virtual keynote last year.
I think what you are talking about is actually scheduling. Basically, how many pages do we ask from indexing side to be crawled by Googlebot. That’s driven mainly by the importance of the pages on a site but not by the number of URLs or how many URLs you want to crawl. It doesn’t have anything to do with host load. It’s more like, okay this is just an example, but for example, if this URL lives in a sitemap then we will probably want to crawl it because, crawl it sooner or more often because you deemed that page more important by putting into a sitemap.
How Googlebot Chooses URLs to Crawl
Also in that keynote, Illyes talked about the process Googlebot goes through to determining what gets crawled on a site when Googlebot does visit.
Every single – I will say day but it’s probably not a day, we will create a bucket of URLs that we want to crawl from a site and we fill that bucket with URLs sorted by the signals that we use for scheduling, which is sitemaps, PageRank whatever. And then from the top we start crawling and crawling and crawling and crawling. And if we can finish the bucket, fine. If we see that the server slowed down, then we will stop.
So again, sitemaps and PageRank contribute to this.
Google Ignoring Some Pages When Crawling
It is normal for Google to not index every single page on a site, so this could just be a regular website issue, not something specific to a site’s crawl budget, although it is often crawl budget that site owners blame. But if Googlebot seems to be ignoring some pages within your site, particularly important ones, it is worth investigating.
First, always double check for a rogue noindex tag or a forgotten robots.txt entry blocking Googlebot. Very often, this is the reason for Google not crawling and indexing pages. Even if you are positive this isn’t the reason, double check.
Do a fetch and render of the pages in question. Make sure Googlebot is seeing what you expect it to see. Use both mobile and desktop crawlers, and make sure it isn’t an issue affecting only one but not the other.
Check for duplication – often it is simply Google filtering pages for being identical or near-identical, particularly on product pages.
Lastly, make sure there are links (regular links, not nofollow ones) to the pages in question or that they are included in a sitemap.
Internal Links Impact on Crawl Budget
Internal links also impact crawl budget as they help to determine the pages Google should crawl and with what priority. I asked Gary Illyes from Google for more clarification on the role of internal links on it, since their blog post didn’t talk about it specifically.
“Yes, Internal links do impact crawl budget through crawl demand,” Illyes confirmed to The SEM Post.
Nofollow & Crawl Budget
Some sites have begun using nofollow on internal links for things such as navigation. John Mueller said that sites don’t need to worry about using nofollow for crawl budget purposes unless they have thousands of links of navigation on a page, and he points out that if navigation is that long, there could be usability issues as well.
Google also recommends that sites do not nofollow links on their sites as it also helps Googlebot understand the hierarchy and the importance of specific pages.
Nofollow is probably never the answer, especially on your own site.
Also, if you do not want Google to index specific pages because of the impact to crawl budget, using noindex and robots.txt is a far better strategy. Your links are not the only way Google discovers links, and if you are just using a nofollow, Google could still index them and use the crawl budget on them. And the reverse could happen – you might nofollow links to a particular page and Google simply never crawls or indexes it, which usually isn’t the intention when people nofollow internally.
Noindex & Crawl Budget
Placing a noindex on a page will cause Googlebot to visit those pages much less frequently. Googlebot will generally crawl those pages a few times to check and see if the noindex has been removed.
Google will still periodically ping the page, but it will drop down to a rate of only once every 2 to 3 months.
We will still probe that page every now and then, probably every two months or every three months, we will visit the page again to see if the noindex is still there. But we will very likely not crawl it that often anymore.
However, John Mueller has also said that it doesn’t preserve crawl budget, namely because those pages still are technically crawled on a schedule, even with the noindex in place, just not quite as frequently as some pages. And those pages might have only been crawled infrequently to start with, so adding the noindex tag might have caused no change.
@idanbenor nope.
— John ☆.o(≧▽≦)o.☆ (@JohnMu) November 30, 2016
So Mueller confirms noindex isn’t a viable solution to really impact crawl budget. Instead, think if those pages really need to be there at all, and consider blocking Googlebot from crawling those pages completely. But if those pages have any search traffic at all, you need to take that traffic loss into account.
If you do decide to try using nofollow for crawl budget purposes, it should only be used on pages you consider unimportant and don’t have an important use for in the future. For example, noindexing a seasonal page probably isn’t the best decision if it is a highly important page during some months. While Google will eventually ramp up that indexing, it could still be much slower than you’d prefer for an important page.
If you need to get a page reindexed that has had a long-term noindex on it, your best option is to do a fetch and submit in Google Search Console to try and speed it up.
Canonicals & Crawl Budget
From an SEO perspective, canonicals make a lot of sense. But what about the use of canonicals and their effect on crawl budget?
@bheligman probably not (or not much). we have to pick a canonical & have to crawl the dups to see that they're dups anyway.
— John ☆.o(≧▽≦)o.☆ (@JohnMu) November 30, 2016
Googlebot still needs to crawl all those canonicals – and sometimes Google is discovering new URLs to crawl because they are canonicals – you aren’t going to save Googlebot from crawling them all. Google still needs to determine that they are indeed duplicate and it makes sense to canonical them, and there aren’t any spam issues hiding behind canonicals. There could be a tiny gain, but it doesn’t sound significant.
There are tons of reasons to be using canonicals though, even if it doesn’t save a site’s crawl budget. For example, using canonicals to clean up duplicate content is usually a smart SEO decision.
Crawl Budget & CMS / Forums / eCommerce Software
Many types of content management systems (ie. WordPress), forums and eCommerce software leave a footprint , either in the code or through URL patterns. But does Google recognize common patterns and crawl differently if they identify a particular piece of web software is being used for a website and page?
I asked Gary Illyes from Google about whether this makes a difference or not for crawl budget. “No, we don’t use common patterns,” Illyes confirmed.
Impact of Server Errors
Server errors can reduce your crawl budget, and it is something to keep an eye on. If Google is receiving server errors, it will slow down crawling to a more reasonable rate your site’s server can handle. If your site is very slow to respond or showing server errors, it will usually limit the number of pages Googlebot will crawl.
When your server issues become a longer term issue, when Googlebot is recognizing repeated server errors on pages, it will also eventually slow down crawling of those individual pages until Google might only be checking it every few months.
Because a site owner might not see or notice these types of errors, it is important to check in Google Search Console under Crawl -> Crawl Errors. In fact, a lot of times Googlebot will see a server error that you as a visitor never see.
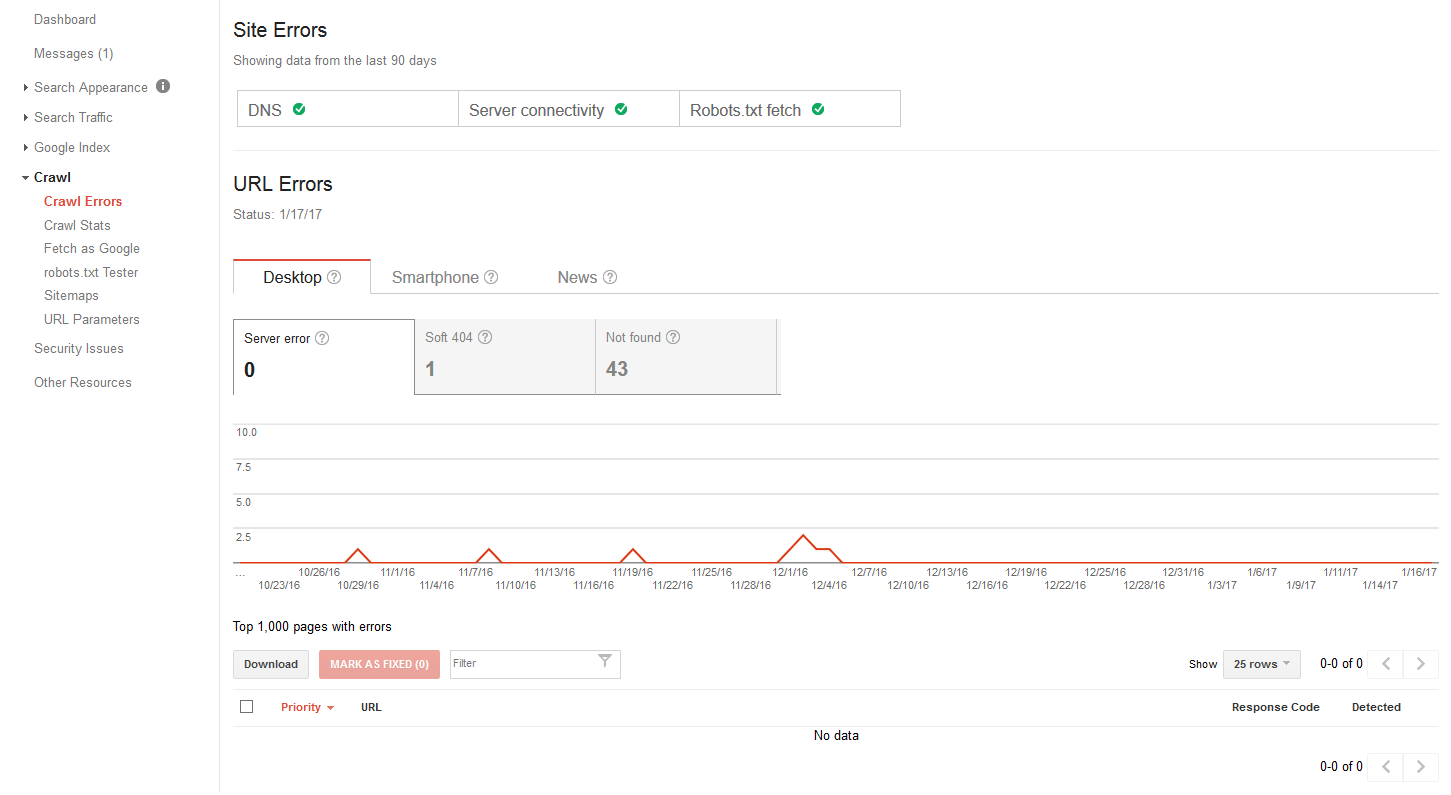
This report will show specific server errors and which pages have them. Don’t forget that sometimes those server errors can be something where your site (or site’s firewall) is giving Googlebot server errors – such as Forbidden – that regular visitors don’t see. It is always worth double checking some of the pages that show server errors with Google’s Fetch & Render (and submit if the errors are fixed) so you can see exactly what Googlebot sees.
Again, never assume that because you don’t see the server errors when you go on the site, that it must be a false positive by Googlebot or a temporary issue. Occasionally it will be one of those one-off situations – perhaps Googlebot crawled exactly as your WordPress site was taking the 20 seconds to update to a new version, or Googlebot tried to access while your hosting company was doing a server restart, and you can often pinpoint those situations. But seeing a few seemingly random server error problems is usually indicative of a larger issue that will become a larger issue when it comes to Google’s ability to crawl your site.
If the problem is severe enough, Google will send a notice about the server errors via Google Search Console.
Lengthy Redirect Chains
Using lengthy redirect chains also impacts crawl budget. Some site owners thought when Google no longer had a PageRank loss calculated into 301 and 302 redirects, that longer redirect chains were no longer an issue. While I probably wouldn’t be worried about having a few of these on a massive site, using a ton of lengthy redirect chains can impact a site well beyond just crawl budget.
Googlebot will only follow 5 301 redirects in a chain – any longer than that, and Googlebot will stop following the redirect chain.
In general, what happens is Googlebot will follow 5 301s in a row, then if we can’t reach the destination page, then we will try again the next time.
In 2011, Matt Cutts recommended only using 1-2 hops in a redirect chain, and that advice still stands for best practices.
Redirect chains can also have a negative impact on your site speed and latency, both from the actual redirect chains the site is sending Googlebot through, and simple user experience. And massively long .htaccess files with massive numbers of redirects can also impact speed.
If you do have redirect chains of 3+ in length, try and reduce that number. Sometimes these long redirect chains are legacy from several redesigns and URL structure changes that have happened over many years.
RankBrain & Crawl Budget
RankBrain is still a misunderstood algorithm in the search results, and Google doesn’t share a lot of details about it. But Google has confirmed that RankBrain does not impact Google’s crawl budget for a site.
Googlebot Ignores Crawl-Delay
Just a reminder, Googlebot ignores the crawl-delay directive some sites attempt to use for Googlebot in their robots.txt. If you wish to slow down Google’s crawling of the site, you need to do that via Google Search Console instead. But for the most part, Google is pretty good at trying not to crawl a server so hard it would impact real visitors to the site.
Changing Googlebot Crawl Rate
Changing Google’s crawl rate in Search Console (in site settings) will not increase Googlebot’s crawling unless you had it previously set to “Limit Google’s maximum crawl rate.” Google recommends this feature is set to “Let Google optimize for my site.”
Fix “Low Value” Pages
Google also says that Googlebot indexing what they specifically call “low-value-add” URLs can negatively impact both a site’s crawl budget and indexing. When Googlebot is forced to crawl these so-called low-value pages, it means that Googlebot might miss crawling your higher quality pages as a result.
These low-value pages also mean that it will take Googlebot longer to discover some of the higher quality pages, especially for new sites, that are more important to you than these low-value ones. If you have pages on the site you don’t care if Google indexes them or not, it might be a good idea to consider removing them or blocking Googlebot from crawling them, so you don’t waste crawl resources on those pages.
Bottom line, you shouldn’t have pages just to add to the page count. Make sure they have value and fix or remove the ones that don’t.
Google specifically refers to some specific page types as using up crawl budget on a site:
Faceted navigation is a common technical issue. When you have pages where multiple options can be changed, such as narrowing down a product search, if each of those individual options can be indexed by Googlebot, for many sites you end up wasting a lot of Googlebot crawl budget for these pages that don’t necessarily benefit the site by being indexed.
Google does have recommendations for sites using faceted navigations that will prevent some of these issues.
Session Identifiers
Session identifiers, which includes session IDs, affiliate tracking codes, URL parameters and tracking parameters, can also impact a site’s crawl budget when Googlebot is suddenly indexing the same URL multiple times with the URLs appended with these extra session identifiers. While this isn’t as common of an issue for many sites these days, it used to be a major headache many years ago for many site owners.
However, many various site programs, shopping carts and the like still run into issues with this, as do issues where advertising tracking URLs go wild and get indexed. If you know you are having issues with these types of URLs getting indexed, Google has information here for webmasters on fixing it.
On-Site Duplicate Content
First, this refers very specifically to duplicate content on your site, not duplicate content from other sites republishing your pages. If you have a lot of identical or near-identical pages being indexed, Google can again be wasting their time crawling and indexing these pages that would be filtered in search.
Try and identify and reduce those duplicate content pages whenever possible. Using a canonical on one version of the page is the most popular solution, or you can take steps to ensure those duplicate or near-duplicate pages are different enough that Googlebot sees them as unique and separate pages.
For sites dealing with near-identical product pages, John Mueller recently talked about what webmasters should do with these types of product pages.
Soft Error Pages / Soft 404s
Soft error pages refers to pages that are seemingly removed or not found, but instead of giving bots the usual 404 status code, they are serving a 200 OK response, but with a blank page or a page that has no “real content” outside of a site template/navigation. But because Google is still crawling them and expecting content, Googlebot is wasting its crawl budget on these pages instead of pages with actual content.
Also avoid the temptation to just redirect all 404s to the homepage, or worse, serve homepage content on those 404 URLs. Instead, serve a true 404 and create a custom 404 page which helps lead visitors to what they might be looking for, such as adding a prominent search bar or perhaps links to your most popular pages.
Google Search Console does have a report showing soft 404s under Crawl -> Crawl Errors. Fixing them means you show Google what it should see – either a true 404 or perhaps there was a technical error that led to the content that should have been shown to disappear – and Google will respond accordingly.
Hacked Pages
If your site is hacked, you should remove those pages from a site and serve Googlebot a 404. Google is quite used to seeing hacked pages and will drop them from the index fairly quickly, as long as you do serve a 404.
There is no reason to ever redirect these formerly hacked URLs to the homepage, something some site owners still do. Google recommends using a 404 once the hacked content is removed.
And no, 404s from hacked pages do not cause any ranking issues.
Infinite Spaces and Proxies
If you have ever gotten a warning from Google Search Console that they have discovered a high number of URLs on your site, it is probably an issue with infinity spaces gone wild.
We see this happen on things like indexed search results, particularly ones with search suggestions that get repeatedly crawled, even when those suggestions also result in no results found. For most sites, you will want to noindex search results, since they are usually indexed under things like category and single product or article pages.
Other examples, which Google includes in a blog post about the issue, are a calendar which can be indexed by the next month forever and product search results where different options could be indexed infinitely.
If you have infinite spaces or are concerned something on your site might go wild if Googlebot takes a run at it, Google shares how to resolve the issues.
You can also discover some of these issues by using a third-party crawler to test for these types of issues, that way you can fix them before they become a Google problem.
Low Quality & Spam Content
This is more self-explanatory. If you have low quality content or spam on your site, either improve the quality or noindex it, or if it is spam, remove it. With Google Panda, Google will downrank this content. For more on Panda, read our Google Panda Algo Guide.
Final Thoughts on Crawl Budget
Not all sites need to worry about crawl budget. If you have a 47 page site and Googlebot hits every one of those pages every day or so, your time is obviously better spent improving your site in other ways. If you have a 47 MILLION page site, then crawl budget will be your SEO friend.
Jennifer Slegg
Latest posts by Jennifer Slegg (see all)
- 2022 Update for Google Quality Rater Guidelines – Big YMYL Updates - August 1, 2022
- Google Quality Rater Guidelines: The Low Quality 2021 Update - October 19, 2021
- Rethinking Affiliate Sites With Google’s Product Review Update - April 23, 2021
- New Google Quality Rater Guidelines, Update Adds Emphasis on Needs Met - October 16, 2020
- Google Updates Experiment Statistics for Quality Raters - October 6, 2020