 Recently, the Google RankBrain system has started to garner quite the buzz within the SEO community — but to a large degree, it’s not entirely being understood. We’ve even had some somewhat link-baity post titles that didn’t help things either. And of course, Google didn’t do itself any favors including the word “rank” in the name.
Recently, the Google RankBrain system has started to garner quite the buzz within the SEO community — but to a large degree, it’s not entirely being understood. We’ve even had some somewhat link-baity post titles that didn’t help things either. And of course, Google didn’t do itself any favors including the word “rank” in the name.
So, let’s start with a statement by Google’s Gary Illyes:
” Lemme try one last time: Rankbrain lets us understand queries better. No affect on crawling nor indexing or replace anything in ranking” – via Twitter

The core, from what we understand, is more about better assessment of queries and the classifications therein. Add to this the potential use of similar concepts to better understand the words, phrases and concepts on a given page, and the outcome should be better results. But for now, let’s take a step back and look at another Google project: Word2Vec.
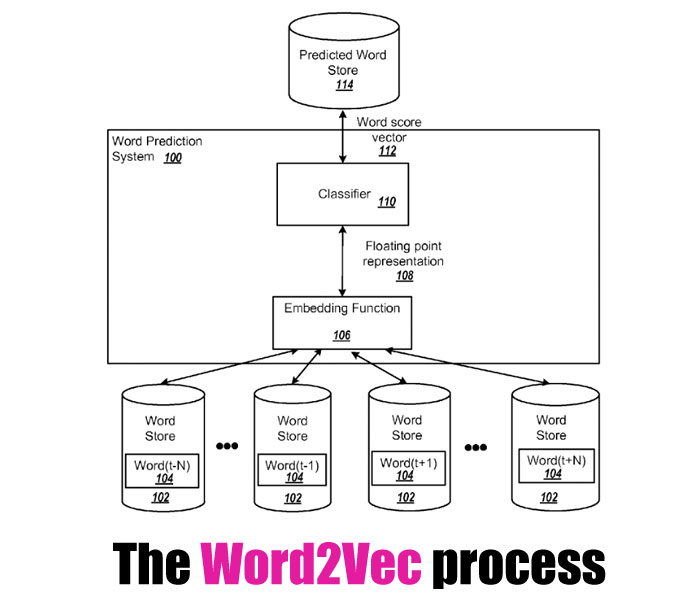
Google’s Word2Vec Project
Essentially, without getting too crazy with it, the Word2Vec project was not a single algorithm, but based from two models: skip-gram and CBOW (continuous bag of words) which are considered “shallow neural models.” The skip-gram is used to predict neighbouring words to a given word while the CBOW tries to predict the current word, based on the neighbouring words. Somewhat opposite but they have the potential to correlate each other.
In fact, much of the conceptual approach was to trade in complexity (in computing models) for efficiency. But let’s not consider this within that simplistic explanation. There’s nothing simple in the various neural network research I’ve read on this. I just wanted to get the basics out of the way before we move onto the meat of the moment.
Another related concept I came across a lot was Distributional Semantics; which essentially can break down into words that co-occur regularly, often tend to share aspects of semantic meaning. There’s also a patent that was awarded last year that is seemingly for W2V since the authors are mostly the same people that worked on the original project.
Hopefully that helps better understand where we’re headed with that.
Probable patent: Computing numeric representations of words in a high-dimensional space
Is Word2Vec really RankBrain?
As with all things Google, it’s hard to say. But again, many of the folks working on RankBrain also worked on the Word2Vec project, and even some of the descriptions of RankBrain are nearly identical to those for the W2V project such as:
The word2vec tool takes a text corpus as input and produces the word vectors as output. It first constructs a vocabulary from the training text data and then learns vector representation of words. The resulting word vector file can be used as features in many natural language processing and machine learning applications.
We also know that RankBrain is “one of the ‘hundreds’ of signals that go into an algorithm that determines what results appear on a Google search page, and where they are ranked,” as stated by Google senior research scientist Greg Corrado in a statement to Bloomberg. The term “signal” is telling to me — it implies it is entirely possible that RankBrain does no direct scoring whatsoever.
Furthermore, most of this machine learning artificial intelligence (AI) seems to be geared towards understanding queries, not really web pages per se. As mentioned in a Daily Mail article;
For example, a user searching for ‘What is low in the army’ is a hard query for the AI to resolve, but RankBrain would interpret it to mean ‘What is low rank in the army’.
Another example shows the search engine may have previous struggles with ‘Why are PDFs so weak?’, taking the search literally and returning results of PDFs containing the word ‘weak’.
Whereas now, RankBrain might interpret it as a question about the security of PDF files, and so returns a better first result.
And so I do have to believe that RankBrain and Word2Vec are related to some degree. For those of us that have studied patents, papers and research projects from Google over the years, both RankBrain and Word2Vec deal with the never ending struggle of semantic analysis; both seek a better understanding of words, phrases and how they relate to each other.
Word Vector Concepts
In the past, semantic analysis approaches would use a simpler word relationship model based on singular relations. The belief with the vector approach is that when trained on larger data-sets with larger dimensionality, it should be more effective. By utilizing 10 examples to form a relationship vector instead of one, semantic accuracy increases.
Again, in the past, semantic analysis was somewhat more simplistic. The belief now is that by using numerical representations of words, they can better predict relationships of words.
In another example, consider that the phrase “Company executive” isn’t necessarily intuitive, but the word vector model would find closest vector relations for:
- Steve Ballmer – Microsoft
- Samuel J. Palmisano – IBM
- Larry Page – Google
- Werner Vogels – Amazon
The main thing to consider is that RankBrain probably isn’t directly ranking anything. It’s trying to better understand concepts related to the words in a query (and presumably on pages it might return). It is also about improving the efficiency of the algorithms therein.
For more, please see my coverage of the Word2vec patent here.
The Artificial Intelligence Angle
Another piece to this puzzle that I came across was the 2011 Google Brain project, which also had some common players in the form of Jeff Dean, Geoffrey Hinton and Greg Corrado.
Google Brain was a deep learning / artificial intelligence research project that may indeed also be part of the evolution of what we know as RankBrain today. As always, it’s hard to say.
Google later acquired Deep Mind, an artificial intelligence company, in 2014. This was considered a talent acquisition at the time, and in retrospect might be much more of an AI tech and research play. This may also have been something that has played a role in the evolution of things.
The Hummingbird connection
I also think that it bears noting that this move is also somewhat in line with Google’s 2013 initiative dubbed “Hummingbird.” At the time, we knew that this new search platform was, among other things, more focused on dealing with queries and natural language processing. This is seemingly being addressed and expanded upon with RankBrain.
As my good friend Bill Slawski penned at the time:
[Hummingbird is] being presented as a query expansion or broadening approach which can better understand longer natural language queries, like the ones that people might speak instead of shorter keyword matching queries which someone might type into a search box.
And as Danny Sullivan reported last fall, in regards to where RankBrain fits in with Hummingbird,
Hummingbird is the overall search algorithm, just like a car has an overall engine in it. The engine itself may be made up of various parts, such as an oil filter, a fuel pump, a radiator and so on. In the same way, Hummingbird encompasses various parts, with RankBrain being one of the newest.
They also might be using it to further improve the Knowledge Graph as well, as noted in this paper (PDF);
Our ongoing work shows that the word vectors can be successfully applied to automatic extension of facts in Knowledge Bases, and also for verification of correctness of existing facts.
From what we understand, RankBrain is actually part of the overall Hummingbird algorithm.
I would also venture a guess that both of these are also in play with an eye towards the future, which is “conversational search” for mobile. Surely they want to be the one that gets that right and leads the way forward.

Does it rank?
This aspect of RankBrain has been more than a bit confusing as well. Obviously, with the word “rank” in the name, it certainly implies such. Also, in talking with Danny Sullivan while crafting this piece, he assured me that “Google has specifically said it is also a ranking factor in addition to query analysis.”
But some statements from Google have seemingly contradicted this claim, including the one from Gary Illyes at the top of this post. So, let’s dig in…
Greg Corrado said in the original Bloomberg article that “RankBrain is one of the ‘hundreds’ of signals that go into an algorithm that determines what results appear on a Google search page and where they are ranked,” which of course further implies that it’s used in rankings (and/or re-ranking).
Certainly, if it’s not a scoring mechanism directly, the signals that it feeds could be used in re-ranking of results (boosting and dampening).
Corrado also mentioned that “RankBrain has become the third-most important signal contributing to the result of a search query.” I am not entirely sure if that is in terms of an actual scoring mechanism? Or that it’s importance is related to the value of better understanding a query and the pages returned in the results. Hard to say.
In short, yes. It would seem, directly or indirectly, that RankBrain is affecting rankings.
Let’s get this clear
So hopefully by now you’re starting to get the idea that RankBrain;
- Is for dealing with unknown or unclear queries
- Is for understanding and predicting related concepts of words
- Is an important signal, but in the sense of serving better results to a query
- It MIGHT be helping to better classify pages
- Is re-ranking based on new classifications
- May NOT be a direct ranking factor
- Does NOT affect crawling nor indexing
- Is NOT affecting other traditional ranking/scoring processes
- It does NOT use machine learning on-the-fly (it’s a push/retraining process)
I have done some exhaustive research into this and there is still a TON of varied opinions floating around the SEO space, and many of them well off base. When Google said it is the “third most important signal,” they seem to mean that it’s a massive part of improving query classification/refinement, which in turn vastly improves search quality. Not all “signals” are scoring mechanisms (ranking factors, for you SEO-types). How it is actually affecting rankings is still unknown. Different Googlers have said different things about that.
For the record, content and links being the other two.
What should I do to leverage RankBrain?
That’s the $64 000 question now isn’t it? Oddly enough, I have been telling people that “if it ain’t broke, don’t fix it” and what I mean by that is if you’re still growing traffic month-over-month with your SEO and marketing efforts, then I wouldn’t get worked up. Apparently Amit Singhal gave the green light for RankBrain to be rolled out back in early 2015. And subsequent statements in the fall of 2015 said it had been active in the wild for a few months.
In short… this isn’t actually something ‘new‘ that we’re dealing with.
And of course all that being said, this is still more about better classification and handling of queries on Google’s end. If anything, it can potentially lessen the need to be overly concerned about what terms you’ve seeded on a page. They can, in theory, better understand the concepts on that page, regardless if that exact word or term is in the query that the user puts into Google.
I’ve long encouraged SEOs and content creators to be more focused on solidifying concepts and entities, than on exact match targeting approaches. So, my advice really won’t be changing in light of RankBrain.
More RankBrain Reading
- RankBrain: Everything We Know About Google’s AI Algorithm
- Investigating Google RankBrain and Query Term Substitutions
- Google’s Gary Illyes On RankBrain Replacing Links & Other Ranking Factors
- RankBrain Does Not Impact Site’s Crawl Budget
- RankBrain is For Understanding Queries, Not for Crawling or Replacing Ranking
- How RankBrain Changes Entity Search
More reading on Word2Vec
Other Reading
- Efficient estimation of word representations in vector space
- Distributed Representations of Words and Phrases
and their Compositionality (pdf) Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado, and Jeffrey Dean. - “Efficient Estimation of Word Representations in Vector Space” (PDF) Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean.
Videos worth watching
Notable people
David Harry
Latest posts by David Harry (see all)
- How Hackers are Hiding Content & Links via PNG Files - January 25, 2018
- Getting Your Head Around Google’s RankBrain - March 28, 2016
Tony Dimmock says
Superb study, commentary and resources David. Thanks for setting the record straight – let’s hope there’s an end to click-bait RB posts now.
I’ll be referencing this post with fellow SEO’s and clients in the future.
Another research paper here: https://www.cs.ubc.ca/~murphyk/Papers/kv-kdd14.pdf “Knowledge Vault: A Web-Scale Approach to Probabilistic Knowledge Fusion” includes Thomas Strohmann and mentions the following:
at point 4.2 (Neural Network Model (MLP):
“To illustrate that the neural network model learns a meaningful “semantic” representation of the entities and predicates, we can compute the nearest neighbors of various items in the a K-dimensional space. It is known from previous work (e.g., [27]) that related entities cluster together in the space, so here we focus on predicates. The results are shown in Table 4. We see that the model learns to put semantically related (but not necessarily similar) predicates near each other. For example, we see that the closest predicates (in the ~w embedding space) to the ’children’ predicate are ’parents’, ’spouse’ and ’birth-place’.”
and point 4.3 (Fusing the Priors):
“We can combine the different priors together using the fusion method described in Section 3.2. The only difference is the features that we use, since we no longer have any extractions. Instead, the feature vector contains the vector of confidence values from each prior system, plus indicator values specifying if the prior was able to predict or not. (This lets us distinguish a missing prediction from a prediction score of 0.0.) We train a boosted classifier using these signals, and calibrate it with Platt Scaling, as before.”
Both comments are possibly key considerations (or a front-runner) to the development of RankBrain (note this paper was published in 2014).
Again, thanks for being as detailed as needed 🙂
Paulo says
congratulations! great post and very complete argumentation.
how do you think that RankBrain information is served right now? Humanly, with some team inserting info on a database, or algorithmcally, with AI being tested?
Nikolay Stoyanov says
Awesome article David! I read it like three times already. However, as it is with RankBrain, there is still a lot more questions to be asked. What are your thoughts on its impact on on-page SEO? I mean, they told us that it is one of thee most important ranking signals. But, will it change the way articles are written?